

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
机器学习中,从获得数据到模型正式放入模型之前,以下哪个选项不是这个过程的一部分()
A.数据标准化
B.教据降维
C.数据可视化
D.数据清理
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
A.数据标准化
B.教据降维
C.数据可视化
D.数据清理
答案
 更多“机器学习中,从获得数据到模型正式放入模型之前,以下哪个选项不是这个过程的一部分()”相关的问题
更多“机器学习中,从获得数据到模型正式放入模型之前,以下哪个选项不是这个过程的一部分()”相关的问题
第2题
A.搜集大数据——分析学习模型——输入学习建议
B.输出大数据——构建学习模型——输入学习建议
C.输出大数据——构建学习模型——输出学习建议
D.搜集大数据——构建学习模型——输出学习建议
第3题
根据美国的米勒提出的科学素养三维模型理论,下列哪项不属于科学能力?
A 获得学术头衔
B 学习和理解科学知识
C 掌握科学方法
D 建立科学价值观
第4题
本题要用到MLB1.RAW中的数据。
(i)从以下模型中去掉变量rbisyr。hrunsyr的统计显著性会如何变化?hrunsyr的系数大小又会如何变化?
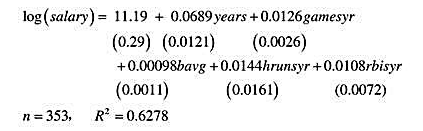
(ii)在第(i)部分的模型中增加变量rusyr(每年垒得分),fldperc(防备率)和sbasesyr(每年盗垒数)。这些因素中,哪一个是个别显著的?
(ii)在第(ii)部分的模型中,检验bavg,fldperc和sbasesyr的联合显著性。
第5题
(i)令yt代表真实个人可支配收入。用直至1989年的数据估计如下模型:
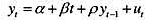
并用通常的格式报告结果。
(ii)用第(i)部分估计的方程预测1990年的y。预测误差是多少?
(iii)用第(i)部分估计的参数,计算20世纪90年代提前一期预测值的MAE。
(iv)把yt-1从方程中去掉后,计算相同时期内的MAE。在模型中包含yt-1更好些吗?
第6题
第7题
利用TRAFFIC2.RAW中的月度数据估计如下方程::

prcfat是事故导致的死亡率,spdlaw是一个虚拟变量,当车速增大到每小时65英里时取1,而beltlaw是另一个虚拟变量,当强制性的安全带政策被履行时取1。由于数据是月度数据,因此回归中还包括一系列月度的虚拟变量(未写出)以及失业率和一个月中的周末数(也未写出)。方程中的标准差是OLS估计中得到的标准差。
(i)通过上面的静态模型,安全带政策对于事故导致的死亡率有什么长期影响?影响是否显著?如果要得到更小的标准差,你应该怎么做?
(ii)通过动态模型,安全带政策对于事故导致的死亡率有什么长期影响?这个结果与静态模型中得到的结果相比有什么不同?
(iii)当二阶滞后项prcfat-2和一阶滞后项prcfat-1同时加入到模型中时,prcfat-2的系数是0.098,而标准差是0.110。在这种情况下,prcfat-2是否需要加入到模型中?
第9题
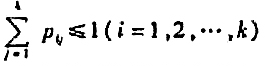 ,而扩散到k个城市之外的那部分污染物永远不再回来.在每个时刻各城市的污染源都排出一定的污染物,记vi排出的为di.按照环境管理条例要求,对充分大的t必须
,而扩散到k个城市之外的那部分污染物永远不再回来.在每个时刻各城市的污染源都排出一定的污染物,记vi排出的为di.按照环境管理条例要求,对充分大的t必须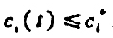 ,试建立马氏链模型,在已知pij和i的条件下确定d的限制范围,满足管理条例的要求。设k=3,pij由矩阵
,试建立马氏链模型,在已知pij和i的条件下确定d的限制范围,满足管理条例的要求。设k=3,pij由矩阵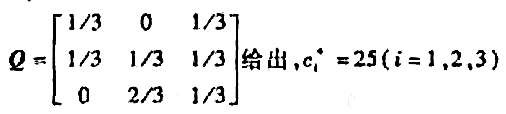 ,求di的范围.
,求di的范围.
第10题
第11题
本题利用401KSUBS.RAW中的数据。
(i) 计算样本中nettfa的平均值、标准差、最小值和最大值。
(ii) 检验假设平均nettfa不会因为401(k) 资格状况而有所不同, 使用双侧对立假设。估计差异的美元数量是多少?
(iii)根据计算机习题C7.9的第(ii)部分,e401k在一个简单回归模型中显然不是外生的,起码它随着收入和年龄而变化。以收入、年龄和e40lk作为解释变量估计nettfa的一个多元线性回归模型。收入和年龄应该以二次函数形式出现。现在,估计401(k)资格的美元效应是多少?
(iv) 在第(iii) 部分估计的模型中, 增加交互项e401k·(age-41) 和e401k·(age-41)2 。注意样本中的平均年龄约为41岁,所以在新模型中,e401k的系数是401(k)资格在平均年龄处的估计效应。哪个交互项显著?
(v)比较第(iii)和(iv)部分的估计值,401(k)资格在41岁处的估计效应差别大吗?请解释。
(vi) 现在, 从模型中去掉交互项, 但定义5个家庭规模虚拟变量:fsize l, j size2,f size 3, f size 4和f size 5。对有5个或5个以上成员的家庭, fsize 5等于1。在第(iii) 部分估计的模型中, 增加家庭规模虚拟变量, 记得选择一个基组。这些家庭虚拟变量在1%的显著性水平上显著吗?
(vii) 现在, 针对模型
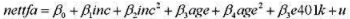
在容许截距不同的情况下, 做5个家庭规模类别的邹至庄检验。约束残差平方和SSR, 从第(vi) 部分得到,因为那里回归假定了相同斜率。无约束残差平方和SSRUR=SSR1+SSR2 +…+SSR5 , 其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。



















